|

Competition Instructions -
Register your email
Please enter your email to
receive the login information to download the dataset, access the
datasets and descriptions of previous competitions (NN3, NN5) and to receive
future announcements. (Please note,
that your old login information for the NN3 and NN5 competitions will still allow you
to access the old datasets and presentations, but not the new datasets
of NN GC1!):
-
Select one or more Dataset
The competition will offer
18 datasets consisting of 11 time series each. These 18 datasets
are predicted in 3 distinct tournaments to be held in 2009 and
2010. The datasets will be released in groups of 6
datasets in different stages during 2009-2010, which we consider
an individual 'tournament'. Each of the three tournaments will include 6
datasets of 11 homogeneous time series with a different time series frequencies:
Each dataset has a homogeneous time frequency, including
low-frequency time series of yearly data (NNG-A), quarterly data (NNG-B)
and monthly data time (NNG-C), and high-frequency time series of
weekly data (NNGC1-D), daily data (NNG-E) and hourly data (NNG-F).
Only a small subset, one to a maximum of 6 datasets, have to be
predicted at any time. All time series within a dataset
represent empirical transportation data with an identical time
series frequency, e.g. all monthly or all hourly data.
Each set of 6 datasets
represents a complete tournament that allows the evaluation of
forecasting accuracy of a particular method across up to 66 time
series of different time frequencies. Participants can choose to
participate only in a single dataset (e.g. 11 series) or multiples
thereof, a single complete time series frequency (e.g. 33 time
series) or multiples thereof, a complete tournament (e.g. 66 series)
or - ideally - all tournaments and all time series!
| Dataset
|
Tournament 1 |
Tournament 2 |
Tournament 3 |
Dataset Winners |
| NNG-A -
Yearly |
1.A 11 series |
2.A 11 series |
3.A 11 series |
x.A 33 time series |
| NNG-B -
Quarterly |
1.B 11 series |
2.B 11 series |
3.B 11 series |
x.B 33 time series |
| NNG-C -
Monthly |
1.C 11 series |
2.C 11 series |
3.C 11 series |
x.C 33 time series |
| NNG-D -
Weekly |
1.D 11 series |
2.D 11 series |
3.D 11 series |
x.D 33 time series |
| NNG-E -
Daily |
1.E 11 series |
2.E 11 series |
3.E 11 series |
x.E 33 time series |
| NNG-F -
Hourly |
1.F 11 series |
2.F 11 series |
3.F 11 series |
x.F 33 time series |
|
Tournament Winner |
1.x winner
66 series |
2.x winner
66 series |
3.x winner
66 series |
Grand Total Winner
198 time series |
In order to limit the
effort into building models for the competition the datasets of each
tournament will be released sequentially, releasing 2 datasets
of a tournament every 3 months. The datasets will be
released in these three stages (of 2 datasets each) in order to you to focus your
time and attention on each set separately. Datasets C and E are
similar in structure
to the NN3 and NN5 competitions of monthly and daily data
respectively, in order to
to reflect experiences and learning from past
competitions and to
allow participants to explore their previously developed
algorithms on this new but similar data.
Choose one, two, three,
four, five or all six datasets of a tournament! Only those forecasting
multiple datasets (either all sets per tournament or at least 2
datasets across all 3 tournaments) will be eligible to win the
competition!
- Download the data
- Click on the
download link below and enter your login & password in
the dialog-box (case sensitive entry!) to
download the datasets. The login is provided in step 1 when
you register your email-address and personal details.
- The datasets have
the following format:
-
a)
each
dataset on a different excel-file
-
b)
one
series per column
-
c)
for each
series:
-
Series identification
-
Number of observations (N)
-
Starting Date
-
Ending Date
-
Description of the time series
-
Observations per smallest seasonal cycle
(e.g. days per week, hours per day)
-
Time Series with N observations, one per cell,
vertically
Currently, only 2 datasets
of Tournament 1 are released - datasets 1.C (monthly) and 1.E
(daily). Additional datasets will be made available here with
information sent to registered members of this site.
If you encounter any problems in submitting please
contact
sven.crone@neural-forecasting.com
immediately!
General Instructions -
Submissions are restricted to one entrance per competitor.
-
The competitors must certify upon submission that they didn’t try to
retrieve the original data.
-
As this is predominantly an academic competition, all advertising based
upon or referencing the results or participation in this competition
requires prior written consent from the organisers.
Submitting your predictions to us
will not automatically allow you to present your method at a conference. In
addition to submitting, we therefore encourage you to submit to one of the
conferences where we will host special sessions. This will allow you to Please check back here
regularly for information on submission deadlines & dates for theses
conferences.
Experimental Design
The competition design and dataset adhere to previously identified
requirements to derive valid and reliable results. -
Evaluation on multiple time series, using 11 and 111 daily time series
-
Representative time series structure for cash machine demand
-
No domain knowledge, no user intervention in the forecasting methodology
-
Ex ante (out-of-sample) evaluation
-
Single time series origin (1-fold cross validation) in order to limit
effort in computation & comparisons
-
Fixed time horizon of 56 days into the future t+1, t+2, ..., t+56
-
Evaluation using multiple, unbiased error measures
-
Evaluation of "novel" methods against established statistical methods &
software benchmarks
-
Evaluation of "novel" methods against standard Neural Networks software
packages
-
Testing of conditions under which NN & statistical methods perform well
(using multiple hypothesis)
Datasets
Two datasets are provided, which may be found [here].
Methods
The competition is open to all methods from Computational Intelligence,
listed below. The objective requires a single methodology, that is
implemented across all time series. This does not require you to build a
single neural network with a pre-specified input-, hidden and output-node
structure but allows you to develop a process in which to run tests and
determine a best setup for each time series. Hence you can come up with 111
different network architectures, fuzzy membership functions, mix of ensemble
members etc. for your submission. However, the process should always lead to
selecting the same final model structure as a rigorous process. -
Feed forward Neural Networks (MLP etc.)
-
Recurrent Neural Networks (TLRNN, ENN, ec.)
-
Fuzzy Predictors
-
Decision & Regression Trees
-
Particle Swarm Optimisation
-
Support Vector Regression (SVR)
- Evolutionary & Genetic
Algorithms
-
Composite & Hybrid approaches
- Others
These will be evaluated against established statistical forecasting methods -
Naïve
-
Single, Linear, Seasonal & Dampened Trend Exponential Smoothing
-
ARIMA-Methods
Statistical benchmarks will be calculated using the software AUTOBOX and ForecastPro,
two of the leading expert system software packages for automatic
forecasting (provided by courtesy of Dave Reilly and Eric Stellwagen
-THANKS!). We hope to also evaluate a number of additional
packages: SAS, NeuralWorks (pending), Alyuda Forecatser (peding),
NeuroDimensions (pending). In addition, the competition is open for
submissions from statistical benchmark methods. Although these can be
submitted and evaluated as benchmarks, only methods from computational
intelligence are eligible to "win".
Evaluation
We assume no particular
decision problem of the underlying forecasting competition and hence assume
symmetric cost of errors. To account for a different number of observations
in the individual data sub-samples of training and test set, and the
different scale between individual series we propose to use a mean
percentage error metric, which is also established best-practice in industry
and in previous competitions. All submissions will be evaluated using the
mean Symmteric Mean Absolute Percent Error (SMAPE) across al time series.
The SMAPE calculates the symmetric absolute error in percent between the
actuals X and the forecast F across all
observations t of the test set of size n for
each time series s with
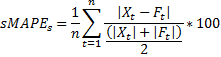 (attention: corrected formula from previously published flawed error
measure)
(attention: corrected formula from previously published flawed error
measure)The SMAPE
of each series will then be averaged over all time series in the dataset for
a mean SMAPE. To determine a winner, all submissions will be ranked by mean
SMAPE across all series. However, biases may be introduced in selecting a
“best” method based upon a single metric, particularly in the lack of a true
objective or loss function. Therefore, while our primary means of ranking
forecasting approaches is mean SMAPE, alternative metrics will be used so as
to guarantee the integrity of the presented results. All submitted forecasts
will also be evaluated on a number of additional statistical error measures
in order to analyse sensitivity to different error metrics. Additional
Metrics for reporting purposes include:
-
Average SMAPE (main metric to determine winner)
- Median SMAPE
-
Median absolute percentage error (MdAPE)
- Median relative absolute error (MdRAE)
-
Average Ranking based upon the error measures
- …
Publication &
Non-Disclosure of Results
We respect the decision of individuals to withhold their name should they
feel unsatisfied with their results. Therefore each contestant reserves the
right to withdraw their name and software package used after they have
learned their relative rank on the datasets. However, we reserve the right
to publish an anonymised version of the descriptions of themethod and methodology used, i.e. MLP, SVR etc
without the name of the contributor.
|
|
